
Simple soml performance numbers
These benchmarks were made to establish places for optimizations. This early on it is clear that performance is not outstanding, but still there were some surprises.
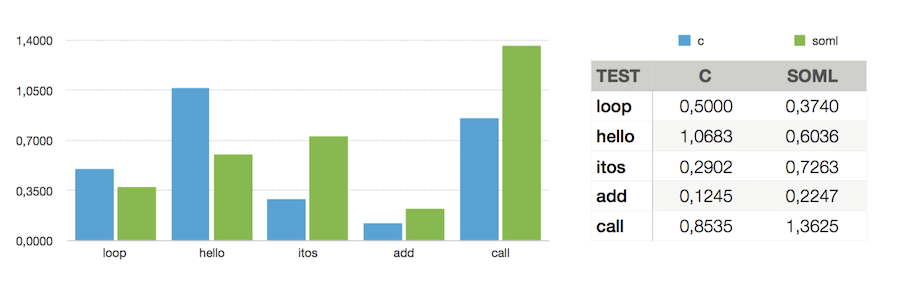
- loop - program does empty loop of same size as hello
- hello - output hello world (to dev/null) to measure kernel calls (not terminal speed)
- itos - convert integers from 1 to 100000 to string
- add - run integer adds by linear fibonacci of 40
- call - exercise calling by recursive fibonacci of 20
Hello and itos and add run 100_000 iterations per program invocation to remove startup overhead. Call only has 10000 iterations, as it is much slower, executing about 10000 calls per invocation
Gcc used to compile c on the machine. soml executables produced by ruby (on another machine)
Results
Results were measured by a ruby script. Mean and variance was measured until variance was low, always under one percent.
The machine was a virtual arm run on a powerbook, performance roughly equivalent to a raspberry pi. But results should be seen as relative, not absolute (some were scaled)
Discussion
Surprisingly there are areas where soml code runs faster than c. Especially in the hello example this may not mean too much. Printf does caching and has a lot functionality, so it may not be a straight comparison. The loop example is surprising and needs to be examined.
The add example is slower because of the different memory model and lack of optimisation for soml. Every result of an arithmetic operation is immediately written to memory in soml, whereas c will keep things in registers as long as it can, which in the example is the whole time. This can be improved upon with register code optimisation, which can cut loads after writes and writes that that are overwritten before calls or jumps are made.
The call was expected to be larger as a typed model is used and runtime information (like the method name) made available. It is actually a small price to pay for the ability to generate code at runtime and will off course reduce drastically with inlining.
The itos example was also to be expected as it relies both on calling and on arithmetic. Also itos relies heavily on division by 10, which when coded in cpu specific assembler may easily be sped up by a factor of 2-3.
All in all the results are encouraging as no optimization efforts have been made. Off course the most encouraging fact is that the system works and thus may be used as the basis of a dynamic code generator, as opposed to having to interpret.